










請連到
http://trac.nchc.org.tw/cloud/wiki/III131207/Lab2
Hadoop國網中心
http://hadoop.nchc.org.tw/
2013年12月17日 星期二
2013年11月16日 星期六
雲端運算平台—Hadoop
作者:周秉誼 / 臺灣大學計算機及資訊網路中心作業管理組碩士後研究人員
再更仔細地介紹流程中每一步的細節,一開始需要建立一個JobConf類別的物件,用來設定運算工作的內容,如 setMapperClass/setReducerClass設定 Mapper及Reducer 的類別,setInputFormat/setOutputFormat 設定輸出輸入資料的格式, setOutputKeyClass / setOutputValueClass 設定輸出資料的類型,設定完成後,依設定內容提交運算工作。資料來源會依InputFormat的設定取得,並分割轉換為一組組的 (key, value) 序對,交由不同的Mapper同時進行運算,Mapper要將運算的結果輸出為一組組(key, value) 序對,也稱為中介資料 (intermediate),系統會將這些暫時的結果排序 (sort) 並暫存起來,等到所有Mapper的運算工作結束之後,依照不同的key值傳送給不同的Reducer彙整,所有同一key值的中介資料的value值,會放在一個容器 (container) 裡傳給同一個Reducer處理,所以在Reducer中可以利用values.next()依序取得不同value值,快速地完成結果整理,再依OutputFormat的設定輸出為檔案。
進行運算的Mapper和Reducer會由系統會自動指派不同的運算節點擔任,所以程式設計時完全不用做資料和運算的切割 (decomposition),運算資源會由JobTracker分配到各個運算節點上的TaskTracker,並指派不同的節點擔任Mapper和Reducer。
HDFSHadoop Distributed File System (HDFS) 將分散的儲存資源整合成一個具容錯能力、高效率且超大容量的儲存環境,在Hadoop系統中大量的資料和運算時產生的暫存檔案,都是存放在這個分散式的檔案系統上。
HDFS是master/slave架構,由兩種角色組成,Name node及data nodes,Name node負責檔案系統中各個檔案屬性權限等資訊 (metadata, namespace) 的管理及儲存;而data node通常由數以百計的節點擔任,一個資料檔會被切割成數個較小的區塊 (block) 儲存在不同的data node上,每一個區塊還會有數份副本 (replica) 存放在不同節點,這樣當其中一個節點損壞時,檔案系統中的資料還能保存無缺,因此name node還需要紀錄每一份檔案存放的位置,當有存取檔案的需求時,協調data node負責回應;而有節點損壞時,name node也會自動進行資料的搬遷和複製。
HDFS雖然沒有整合進Linux kernel,只能透過Hadoop的dfs shell進行檔案操作,或使用FUSE成為User space下的檔案系統,但Hadoop下的系統都與HDFS整合,做為資料儲存備份及分享的媒介。如前面提到的MapReduce在系統分配運算工作時,會將運算工作分配到存放有運算資料的節點上進行,減少大量資料透過網路傳輸的時間。
HBaseHBase是架構在HDFS上的分散式資料庫,與一般關聯式資料庫 (relational database) 不同。HBase使用列 (row) 和行 (column) 為索引存取資料值,因此查詢的時候比較像在使用map容器 (container);HBase的另一個特點是每一筆資料都有一個時間戳記 (timestamp),因此同一個欄位可依不同時間存在多筆資料。
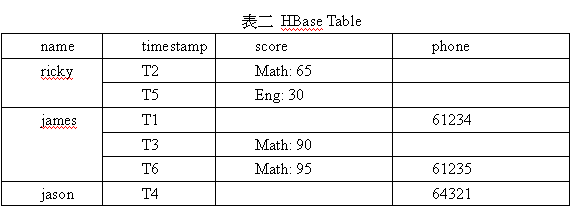
一個HBase的資料表 (table) 是由許多row及數個column family組成,每個列都有一個row key做為索引;一個column family就是一個column label的集合 (set),裡面可有很多組label,這些label可以視需要隨時新增,而不用重新設定整個資料表 (見表二)。在存取資料表的時候,通常就使用 (‘row key’, ‘family:label’) 或 (‘row key’, ‘family:label’, ‘timestamp’) 的組合取出需要的欄位。
HBase為了方便分散資料和運算工作,又將整個資料表分為許多region,一個region是由一到數個列所組成的,可以分別存放在不同HBase主機上,這些存放region的主機就是region server,另外還有master server用來紀錄每一個region對應的region server;master server也會自動將不能提供服務的region server上的region重新分配到其他的region server上。
HBase也可供MapReduce的程式當作資料來源或儲存媒介,在HBase 0.20版之後提供了TableMapper及TableReducer的類別讓程式中的Mapper及Reducer類別繼承,可以把MapReuce中的 (key, value) 更方便地從HBase中取出和存入。
雲端運算是資料中心因應網路上資訊暴增而提出的服務及管理思維,資訊服務提供者投入資源進行雲端運算的服務及架構開發,Google可說是最大量使用雲端運算的組織之一。Hadoop就是由Google雲端架構得到啟發而開始的開放原始碼計劃,目前有許多組織參與Hadoop的研究開發,並以Hadoop做為雲端運算的平台。
前言隨著網際網路 (Internet) 的發展,及web2.0概念被提出,網路使用者的行為也由單純的瀏覽轉變為創作與分享;另外,行動式的資訊設備也越來越多,為了方便分享及取用,使用者們把資料從個人的電腦中轉移到web服務提供者的資料中心 (Data Center);而服務提供者為了提供更穩定更迅速的服務,也需要一個新的服務架構,將運算資源及儲存空間更有效率的利用,同時提供服務開發人員更便利的開發環境。
雲端運算 (Cloud Computing) 就是將前述所有的需求整合在一起的概念,一個面向是讓使用者以更加便利的方式使用及取得服務,甚至用最簡單的方式開發新的服務。隨著各種雲端服務產生,對於運算能力及儲存空間的需求,也會驚人地成長,因此雲端運算的另一個面向就是整合組織內部運算資源,以最有效率、最易於管理的方式,提供雲端服務穩定的運算及儲存能量。
以Google為例,許多服務都以雲端運算的形式推出,讓使用者隨時可以取得自己的資料,也能夠透過網路跟其他人分享;還提供了相當便利的開發環境,如 Google App. Engine提供了介面和免費的運算及儲存資源,讓使用者開發各種有趣的web服務。但這些服務需要十分可觀的運算能力和使用者資料的儲存空間,因此,Google開發了許多雲端運算的技術與架構,如MapReduce以分散式運算提供整合的運算資源及減少運算時間、Google File System將大量而分散的儲存空間整合為一個可靠的儲存媒介、BigTable提供高效率的分散式資料庫。這些技術及架構都有一個特點,就是讓服務開發人員不用考慮在這些分散式系統上資料要怎麼放置、運算要怎麼切割,只需要專注在服務的開發就可以了,而資料與運算的切割及分散就交給雲端運算的架構來處理,可說是大大增加了開發服務的速度。
以Google為例,許多服務都以雲端運算的形式推出,讓使用者隨時可以取得自己的資料,也能夠透過網路跟其他人分享;還提供了相當便利的開發環境,如 Google App. Engine提供了介面和免費的運算及儲存資源,讓使用者開發各種有趣的web服務。但這些服務需要十分可觀的運算能力和使用者資料的儲存空間,因此,Google開發了許多雲端運算的技術與架構,如MapReduce以分散式運算提供整合的運算資源及減少運算時間、Google File System將大量而分散的儲存空間整合為一個可靠的儲存媒介、BigTable提供高效率的分散式資料庫。這些技術及架構都有一個特點,就是讓服務開發人員不用考慮在這些分散式系統上資料要怎麼放置、運算要怎麼切割,只需要專注在服務的開發就可以了,而資料與運算的切割及分散就交給雲端運算的架構來處理,可說是大大增加了開發服務的速度。
Hadoop計劃Hadoop是Apache軟體基金會 (Apache Software Foundation) 底下的開放原始碼計劃 (Open source project),最初是做為Nutch這個開放原始碼的搜尋引擎的一部份。Hadoop是以java寫成,可以提供大量資料的分散式運算環境,而且Hadoop的架構是由Google發表的BigTable及Google File System等文章提出的概念實做而成,所以跟Google內部使用的雲端運算架構相似。目前Yahoo!及Cloudera等公司都有開發人員投入Hadoop的開發團隊,也有將近一百個公司或組織公開表示使用Hadoop做為雲端運算平台,Google及IBM也使用Hadoop平台為教育合作環境。
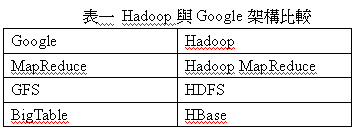
Hadoop中包括許多子計劃,其中Hadoop MapReduce如同Google MapReduce,提供分散式運算環境、Hadoop Distributed File System如同Google File System,提供大量儲存空間、HBase是一個類似 BigTable 的分散式資料庫 (見表一),還有其他部份可用來將這三個主要部份連結在一起,方便提供整合的雲端服務。
Hadoop中包括許多子計劃,其中Hadoop MapReduce如同Google MapReduce,提供分散式運算環境、Hadoop Distributed File System如同Google File System,提供大量儲存空間、HBase是一個類似 BigTable 的分散式資料庫 (見表一),還有其他部份可用來將這三個主要部份連結在一起,方便提供整合的雲端服務。
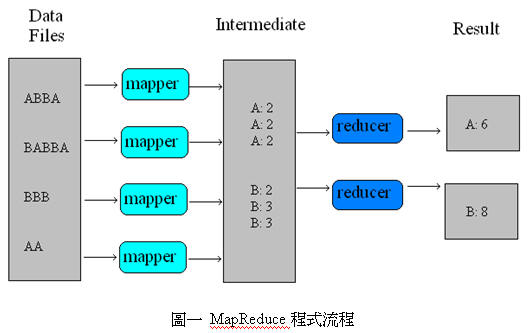
MapReduceMapReduce是一個分散式程式框架,讓服務開發者可以很簡單的撰寫程式,利用大量的運算資源,加速處理龐大的資料量,一個MapReduce的運算工作可以分成兩個部份—Map和Reduce,大量的資料在運算開始的時候,會被系統轉換成一組組 (key, value) 的序對並自動切割成許多部份,分別傳給不同的Mapper來處理,Mapper處理完成後也要將運算結果整理成一組組 (key, value) 的序對,再傳給Reducer整合所有Mapper的結果,最後才能將整體的結果輸出 (見圖一)。
再更仔細地介紹流程中每一步的細節,一開始需要建立一個JobConf類別的物件,用來設定運算工作的內容,如 setMapperClass/setReducerClass設定 Mapper及Reducer 的類別,setInputFormat/setOutputFormat 設定輸出輸入資料的格式, setOutputKeyClass / setOutputValueClass 設定輸出資料的類型,設定完成後,依設定內容提交運算工作。資料來源會依InputFormat的設定取得,並分割轉換為一組組的 (key, value) 序對,交由不同的Mapper同時進行運算,Mapper要將運算的結果輸出為一組組(key, value) 序對,也稱為中介資料 (intermediate),系統會將這些暫時的結果排序 (sort) 並暫存起來,等到所有Mapper的運算工作結束之後,依照不同的key值傳送給不同的Reducer彙整,所有同一key值的中介資料的value值,會放在一個容器 (container) 裡傳給同一個Reducer處理,所以在Reducer中可以利用values.next()依序取得不同value值,快速地完成結果整理,再依OutputFormat的設定輸出為檔案。
進行運算的Mapper和Reducer會由系統會自動指派不同的運算節點擔任,所以程式設計時完全不用做資料和運算的切割 (decomposition),運算資源會由JobTracker分配到各個運算節點上的TaskTracker,並指派不同的節點擔任Mapper和Reducer。
HDFSHadoop Distributed File System (HDFS) 將分散的儲存資源整合成一個具容錯能力、高效率且超大容量的儲存環境,在Hadoop系統中大量的資料和運算時產生的暫存檔案,都是存放在這個分散式的檔案系統上。
HDFS是master/slave架構,由兩種角色組成,Name node及data nodes,Name node負責檔案系統中各個檔案屬性權限等資訊 (metadata, namespace) 的管理及儲存;而data node通常由數以百計的節點擔任,一個資料檔會被切割成數個較小的區塊 (block) 儲存在不同的data node上,每一個區塊還會有數份副本 (replica) 存放在不同節點,這樣當其中一個節點損壞時,檔案系統中的資料還能保存無缺,因此name node還需要紀錄每一份檔案存放的位置,當有存取檔案的需求時,協調data node負責回應;而有節點損壞時,name node也會自動進行資料的搬遷和複製。
HDFS雖然沒有整合進Linux kernel,只能透過Hadoop的dfs shell進行檔案操作,或使用FUSE成為User space下的檔案系統,但Hadoop下的系統都與HDFS整合,做為資料儲存備份及分享的媒介。如前面提到的MapReduce在系統分配運算工作時,會將運算工作分配到存放有運算資料的節點上進行,減少大量資料透過網路傳輸的時間。
HBaseHBase是架構在HDFS上的分散式資料庫,與一般關聯式資料庫 (relational database) 不同。HBase使用列 (row) 和行 (column) 為索引存取資料值,因此查詢的時候比較像在使用map容器 (container);HBase的另一個特點是每一筆資料都有一個時間戳記 (timestamp),因此同一個欄位可依不同時間存在多筆資料。
一個HBase的資料表 (table) 是由許多row及數個column family組成,每個列都有一個row key做為索引;一個column family就是一個column label的集合 (set),裡面可有很多組label,這些label可以視需要隨時新增,而不用重新設定整個資料表 (見表二)。在存取資料表的時候,通常就使用 (‘row key’, ‘family:label’) 或 (‘row key’, ‘family:label’, ‘timestamp’) 的組合取出需要的欄位。
HBase為了方便分散資料和運算工作,又將整個資料表分為許多region,一個region是由一到數個列所組成的,可以分別存放在不同HBase主機上,這些存放region的主機就是region server,另外還有master server用來紀錄每一個region對應的region server;master server也會自動將不能提供服務的region server上的region重新分配到其他的region server上。
HBase也可供MapReduce的程式當作資料來源或儲存媒介,在HBase 0.20版之後提供了TableMapper及TableReducer的類別讓程式中的Mapper及Reducer類別繼承,可以把MapReuce中的 (key, value) 更方便地從HBase中取出和存入。
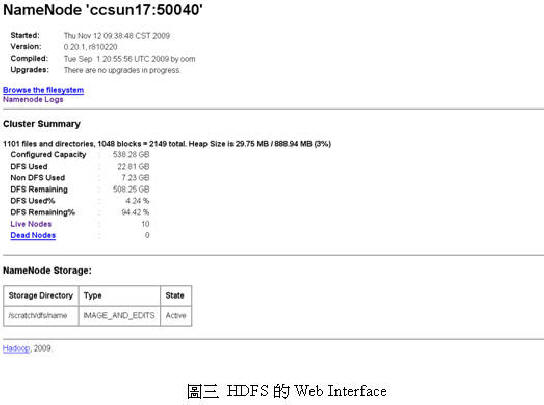
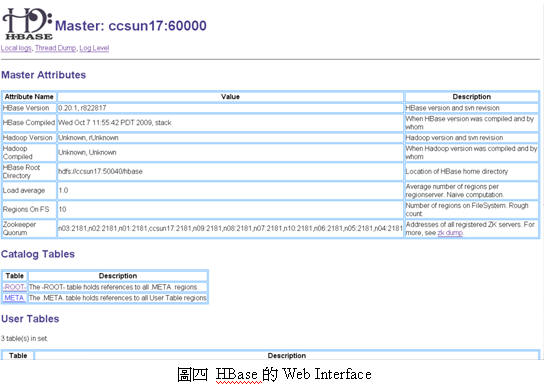
Web InterfaceMapReduce的JobTracker、HDFS、及HBase都有各自的web監控介面,可以及時觀察目前每個運算工作的運作情況、檔案系統的容量、及資料表和region的使用情況, 讓系統管理者輕鬆地監控大量資源 (見圖二、圖三、圖四)。
結論Hadoop是目前最常見且實際運用在大規模商業環境上的雲端運算平台之一,強大而完整的基礎架構可以減少大量的雲端架構開發的時間,大量部署時也相當迅速,不但有許多重量級的雲端運算服務提供者正在使用及投入開發,也與Google的雲端環境相似,使Hadoop成為教育訓練、學術研究及雲端服務開發的最佳平台。
雖然有Hadoop這麼便利的雲端運算環境,又有成功的雲端服務可以參考,然而在組織內部導入雲端運算的架構及文化時,仍需做好充分的規劃及時程表,不然將會影響原有服務的穩定及品質,不但不能享受雲端運算帶來的便利,反而徒然增加管理及營運成本,使雲端運算淪為失敗的行銷名詞。
雖然有Hadoop這麼便利的雲端運算環境,又有成功的雲端服務可以參考,然而在組織內部導入雲端運算的架構及文化時,仍需做好充分的規劃及時程表,不然將會影響原有服務的穩定及品質,不但不能享受雲端運算帶來的便利,反而徒然增加管理及營運成本,使雲端運算淪為失敗的行銷名詞。
訂閱:
文章 (Atom)